
Pycon 2018
Published:
Del 9 al 11 de febrero se desarrolló la segunda versión de la Pycon en Colombia. Tuve la fortuna de ganar una beca para asistir a la conferencia, no conocía mucho sobre el evento pero me llamó la atención algunas charlas sobre audio y machine learning ya que aunque soy ingeniero de sonido, una de mis pasiones es programar además de la inteligencia artificial. Es un poco difícil resumir en este escrito lo ocurrido en 3 dias llenos de aprendizaje y compartir, a continuación, haré un resumen por días de mi recorrido en la conferencia. Este representa mi experiencia, ya que al existir charlas y talleres simultáneos, cada quien elige su agenda y por la tanto su experiencia es única.
Viernes 9
Después del registro inicial en donde recibí unos magníficos souvenirs(Camiseta, manilla, botella…) inició la introducción por parte de John Roa, quien dio un balance de la conferencia del año pasado y los retos para este año. La primera keynote estuvo a cargo del Dr Satya Mallick, creador del blog learnopencv y quien habló sobre diferentes técnicas de procesamiento de imágenes y visión por computadora. Satya mostró algunos ejemplos de face swap, seamless cloning y face morphing, concluyendo con esta frase: “Python es el lenguaje de la IA, Únete a la revolución.”

Asistí luego a una charla de programación asíncrona que era uno de los temas que me inquietaba conocer más fondo, aquí pude aprender la diferencia entre procesos blocking y non-blocking, además de las ventajas que tiene programar de esta manera. Gracias a esto, me fue posible entender el manejo que hace la librería portaudio con las muestras de la tarjeta de audio en los modos blocking y callback que estan soportados.
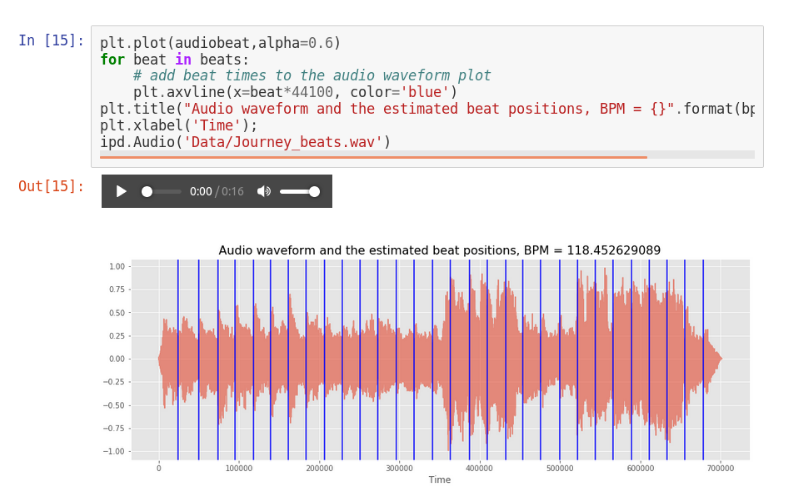
Otra de las charlas que estaba esperando era la de Jose Zapata sobre analisis de señales de audio, fue muy divertida y explicativa pues se hizo una introducción desde como cargar y manipular audios en python hasta aplicaciones más complejas de MIR como beat tracking y separación de fuentes, usando la libreria Essentia
En la tarde Robert kuska se adentró en las profundidades de python sobre el manejo de memoria interna del lenguaje y Christine Doig dió la keynote de cierre del día. En esta última se definieron de una manera clara varios términos asociados con data science y se mostró la evolución de las diferentes librerías en Python desde el 2005 con Numpy hasta llegar a las librerias de deep learning en el 2014. El final estuvo enfocado en los retos del futuro sobre ética, seguridad e interpretabilidad en los modelos que sería una excelente introducción para la keynote del Sábado.
Sabado 10
La keynote de Lorena profundizó sobre las consideraciones éticas y las consecuencias que pueden tener los modelos sesgados en las aplicaciones reales. Desde su experiencia en el campo social explicó a través de casos de Airbnb, tripadvisor y otras redes sociales como las bases de datos sesgadas, pueden generar modelos que reproducen la discriminación existente en el pasado.

Para finalizar la mañana, Manuel franco presentó una interesante charla sobre sistemas de recomendación, en donde introdujo un framework open source para experimentar y explicó los diferentes pasos para construirlos. Las aplicaciones de estos sistemas las vemos a diario en Amazon, Netflix, Spotify y muchas otras plataformas y están directamente relacionadas con la venta y visualización de contenidos como explicó Manuel con el ejemplo de “into the wild” y “touching the void”, que son dos libros con historias muy similares en donde uno es un éxito comercial en contraposición con el otro.
En la tarde elegí quedarme en 3 charlas que abordaban diferentes temas de visión por computador, quería conocer algunas técnicas usadas en este campo para extrapolarlas al dominio del sonido que es donde actualmente trabajo. La que más me gustó fue la de Jorge Martinez, que explicó la diferencia entre un enfoque de detección basado en modelos preentrenados y un enfoque de rastreador con one shot learning, para posteriormente mostrar aplicaciones en vídeos que combinaban las dos técnicas. Me llamó mucho la atención la frase con la que abrió su presentación de Marvin Minsky:
” No computer has ever been designed that is ever aware of what it’s doing; but most of the time, we aren’t either.”
Para Finalizar el día Naomi Ceder dio su keynote sobre obstáculos para inclusión, mediante diferentes preguntas Naomi nos hizo cuestionarnos sobre diferentes actitudes y situaciones en relación con la discriminación. Nos explicó porque la diversidad es buena en los equipos de trabajo, que no basta con tener un equipo diverso si no se tienen estrategias de inclusión, que como seres humanos somos diferentes en muchas dimensiones y debemos trabajar para que esta diferencia en vez de significar un obstáculo para las personas, sea celebrada y aprovechada en el mundo.
Domingo 11
Después de las charlas teóricas el último día estaba dedicado a los talleres prácticos, elegí el de identificación de especies de aves colombianas y el taller práctico de machine learning con sci-kit learn. El primer taller estuvo a cargo de Angie Reyes, aquí trabajamos con una base de datos del concurso LifeCLEF de donde se seleccionaron solo los audios correspondientes a especies colombianas. Durante el taller Angie explicó los diferentes pasos de procesamiento de los audios como la reducción de ruido, los descriptores usados y las metodologías de resumen de los descriptores comparando el cálculo de estadísticas básicas con la bolsa de palabras.
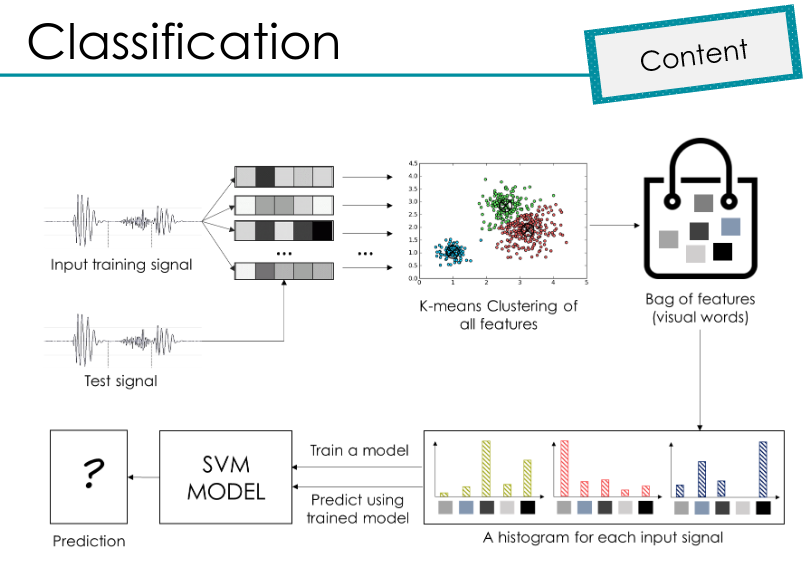
El segundo taller lo dictó Alejandro Correa, la dinámica de este taller fue muy buena porque a través de preguntas al público el tallerista iba introduciendo dudas y explicando el funcionamiento de diferentes algoritmos usados en machine learning. Tambien fue muy satisfactorio que desde su experiencia en el sector financiero nos enseñara ejemplos de aplicaciones que están funcionando con modelos de machine learning que el había creado, específicamente una de detección de urls de phishing.
En la tarde deborah hanus tuvo su keynote en donde se hizo énfasis en la construcción de modelos de machine learning responsables y seguros dando algunos pasos sobre la comprensión y manejo de bases datos del modelo, así como de la interpretabilidad de los resultados. Para finalizar la Pycon la última keynote estuvo a cargo de Audrey y Daniel acerca de como crear un paquete instalable de python a partir de algún código o función propia.

He tratado de resumir lo más importante en mi opinión de la Pycon, pero seguramente se me quedan muchas cosas por fuera de las que viví en estos tres días. La Pycon esta llena de sorpresas y más allá de la información técnica y académica, durante estos días se puede sentir que se hace parte de una comunidad de emprendedores y visionarios diversos dispuestos a ayudar a través de la tecnología.

Muchas Gracias
Recomendaciones
Para quienes quieran aplicar a las becas de Pycon 2019 es necesario concentrarse en las fortalezas que se tienen más que describir necesidades y explicar de que manera nos beneficiará asistir al evento. Es importante tener un perfil en github o algun otro repositorio online para que conozcan nuestro trabajo previo, además de eso, unanse al grupo de facebook de Python Colombia y a las comunidades locales en sus ciudades, asistan a los meetups, lo importante es aprender y compartir. A mi me tomó por sorpresa que me eligieran porque los correos de aceptación llegaron unos dias más tarde de lo previsto, me sentí muy afortunado porque se que seguramente se presentó mucha gente para las becas, agradezco de nuevo al equipo organizador y muchos éxitos en sus aplicaciones.